

Styles of machine learning: Intro to neural networks
Artificial intelligence (AI) is one of the most important and long-lived areas of research in computer science. It’s a broad area with crossover into philosophical questions about the nature of mind and consciousness. On the practical side, present day AI is largely the field of machine learning (ML). Machine learning deals with software systems capable of changing in response to training data. A prominent style of architecture is known as the neural network, a form of so-called deep learning. This article introduces you to neural networks and how they work.
Neural networks and the human brain
Neural networks are inspired by the human brain structure, the basic idea being that a group of objects called neurons are combined into a network. Each neuron receives one or more inputs and a single output based on internal computation. Neural networks are therefore a specialized kind of directed graph.
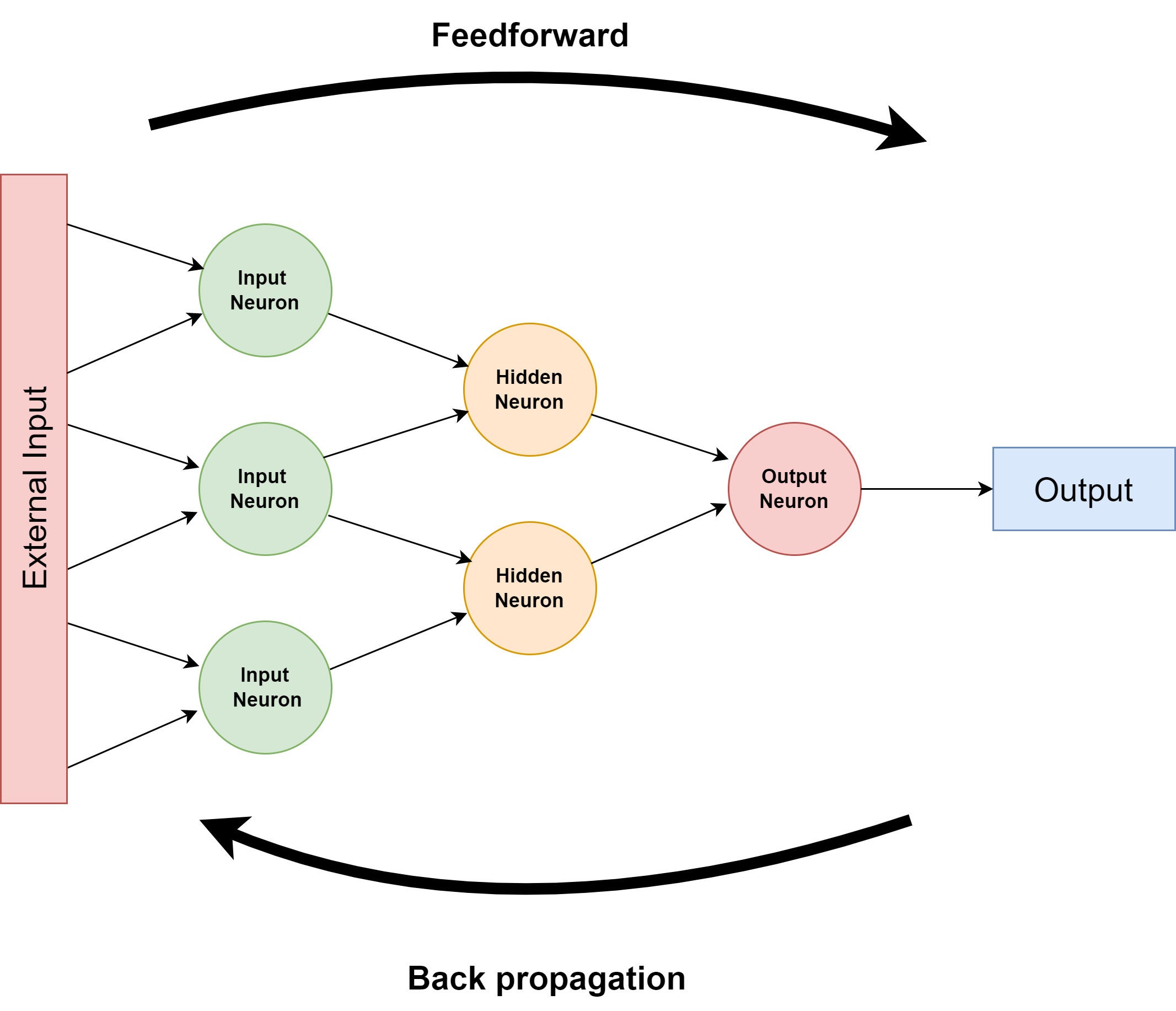
Many neural networks distinguish between three layers of nodes: input, hidden, and output. The input layer has neurons that accept the raw input; the hidden layers modify that input; and the output layer produces the final result. The process of moving data forward through the network is called feedforward.
The network “learns” to perform better by consuming input, passing it up through the ranks of neurons, and then comparing its final output against known results, which are then fed backwards through the system to alter how the nodes perform their computations. This reversing process is known as backpropagation and is a main feature of machine learning in general.
An enormous amount of variety is encompassed within the basic structure of a neural network. Every aspect of these systems is open to refinement within specific problem domains. Backpropagation algorithms, likewise, have any number of implementations. A common approach is to use partial derivatives calculus (also known as gradient backpropagation) to determine the effect of specific steps in the overall network performance. Neurons can have different numbers of inputs (1 – *) and different ways they are connected to form a network. Two inputs per neuron is common.
Figure 1 shows the overall idea, with a network of two-input nodes.
 IDG
IDGFigure 1. High-level neural network structure
Let’s look closer at the anatomy of a neuron in such a network, shown in Figure 2.
 IDG
IDGFigure 2. A two-input neuron
Figure 2 looks at the details of a two-input neuron. Neurons always have a single output, but may have any number of inputs, two being the most common. As input arrives, it is multiplied by a weight property that is specific to that input. All the weighted inputs are then added together with a single value called the bias. The result of those computations is then put through a function known as the activation function, which gives the final output of the neuron for the given input.
The input weights are the main dynamic dials on a neuron. These are the values that change to give the neuron differing behavior, the ability to learn or adapt to improve its output. Bias is sometimes a constant, unchanging property or sometimes a variable that is also modified by learning.
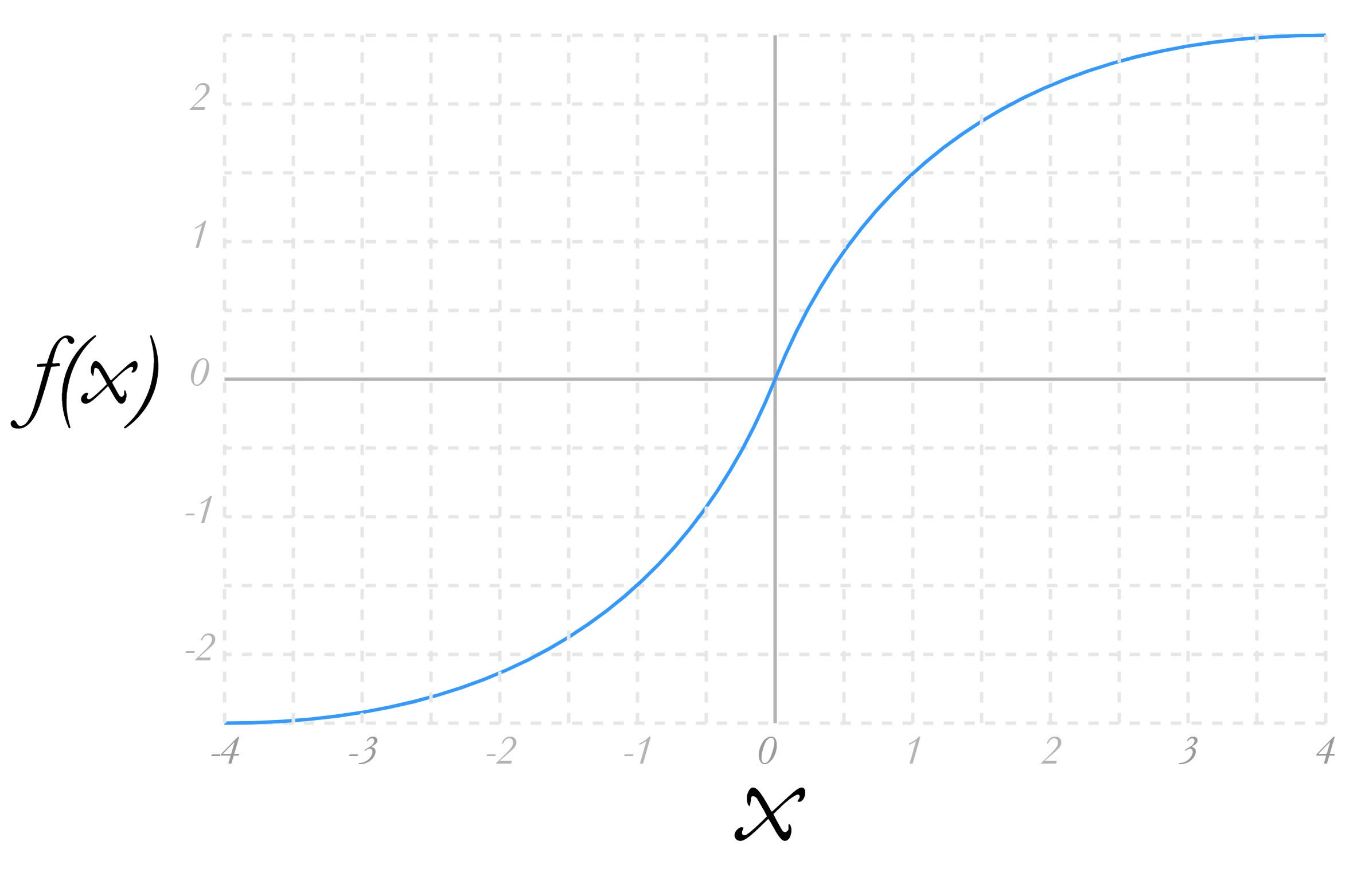
The activation function is used to bring the output within an expected range. This is usually a kind of proportional compression function. The sigmoid function is common.
What an activation function like sigmoid does is bring the output value within -1 and 1, with large and small values approaching but never reaching 0 and 1, respectively. This serves to give the output the form of a probability, with 1 being the most likely out and 0 being the least. So this kind of activation function says the neuron gives n degree of probability to the outcome yes or no.
You can see the output of a sigmoid function in the graph in Figure 3. For a given x, the further from 0, the more dampened the output y will be.
 IDG
IDGFigure 3. Output of a sigmoid function
So the feedforward stage of neural network processing is to take the external data into the input neurons, which apply their weights, bias, and activation function, producing the output that is passed to the hidden layer neurons that perform the same process, finally arriving at the output neurons which then do the same for the final output.
Machine learning with backpropagation
What makes the neural network powerful is its capacity to learn based on input. This happens by using a training data set with known results, comparing the predictions against it, then using that comparison to adjust the weights and biases in the neurons.
Loss function
To do this, the network needs a function that compares its predictions against the known good answers. This function is known as the error, or loss function. A common loss function is the mean squared error function.
The mean squared error function assumes it is consuming two equal-length sets of numbers. The first set is the known true answers (correct output), represented by Y in the equation above. The second set (represented by y’) are the guesses of the network (proposed output).
The mean squared error function says: for every item i, subtract the guess from the correct answer, square it, and take the mean across the data sets. This gives us a way to see how well the network is doing, and to check the effect of making changes to the neuron’s weights and biases.
Gradient descent
Taking this performance metric and pushing it back through the network is the backpropagation phase of the learning cycle, and it is the most complex part of the process. A common approach is gradient descent, wherein each weight in the network is isolated via partial derivation. For example, according to a given weight, the equation is expanded via the chain rule and fine-tunings are made to each weight to move overall network loss lower. Each neuron and its weights are considered as a portion of the equation, stepping from the last neuron(s) backwards (hence the name of the algorithm).
You can think of gradient descent this way: the error function is the graph of the network’s output, which we are trying to adjust so its overall shape (slope) lands as well as possible according to the data points. In doing gradient backpropagation, you stand at each neuron’s function (a point in the overall slope) and modify it slightly to move the whole graph a bit closer to the ideal solution.
The idea here is that you consider the entire neural network and its loss function as a multivariate (multidimensional) equation depending on the weights and biases. You begin at the output neurons and determine their partial derivatives as a function of their values. You then use the calculation to evaluate the same for the next neurons back. Continuing the process on, you determine the role each weight and bias plays in the final error loss, and you can adjust each slightly to improve the results.
See Machine Learning for Beginners: An Introduction to Neural Networks for a good in-depth walkthrough with the math involved in gradient descent.
Backpropagation is not limited to function derivatives. Any algorithm that effectively takes the loss function and applies gradual, positive changes back through the network is valid.
Conclusion
This article has been a quick dive into the overall structure and function of an artificial neural network, one of the most important styles of machine learning. Look for future articles covering neural networks in Java and a closer look at the backpropagation algorithm.