

How to make the most of Apache Kafka
To really understand Apache Kafka—and get the most out of this open source distributed event streaming platform—it’s crucial to gain a thorough understanding of Kafka consumer groups. Often paired with the powerful, highly scalable, highly-available Apache Cassandra database, Kafka offers users the capability to stream data in real time, at scale. At a high level, producers publish data to topics, and consumers are used to retrieve those messages.
Kafka consumers are generally configured within a consumer group that includes multiple consumers, enabling Kafka to process messages in parallel. However, a single consumer can read all messages from a topic on its own, or multiple consumer groups can read from a single Kafka topic—it just depends on your use case.
Here’s a primer on what to know.
Message distribution to Kafka consumer groups
Kafka topics include partitions for distributing messages. A consumer group with a single consumer will receive messages from all of a topics’ partitions:
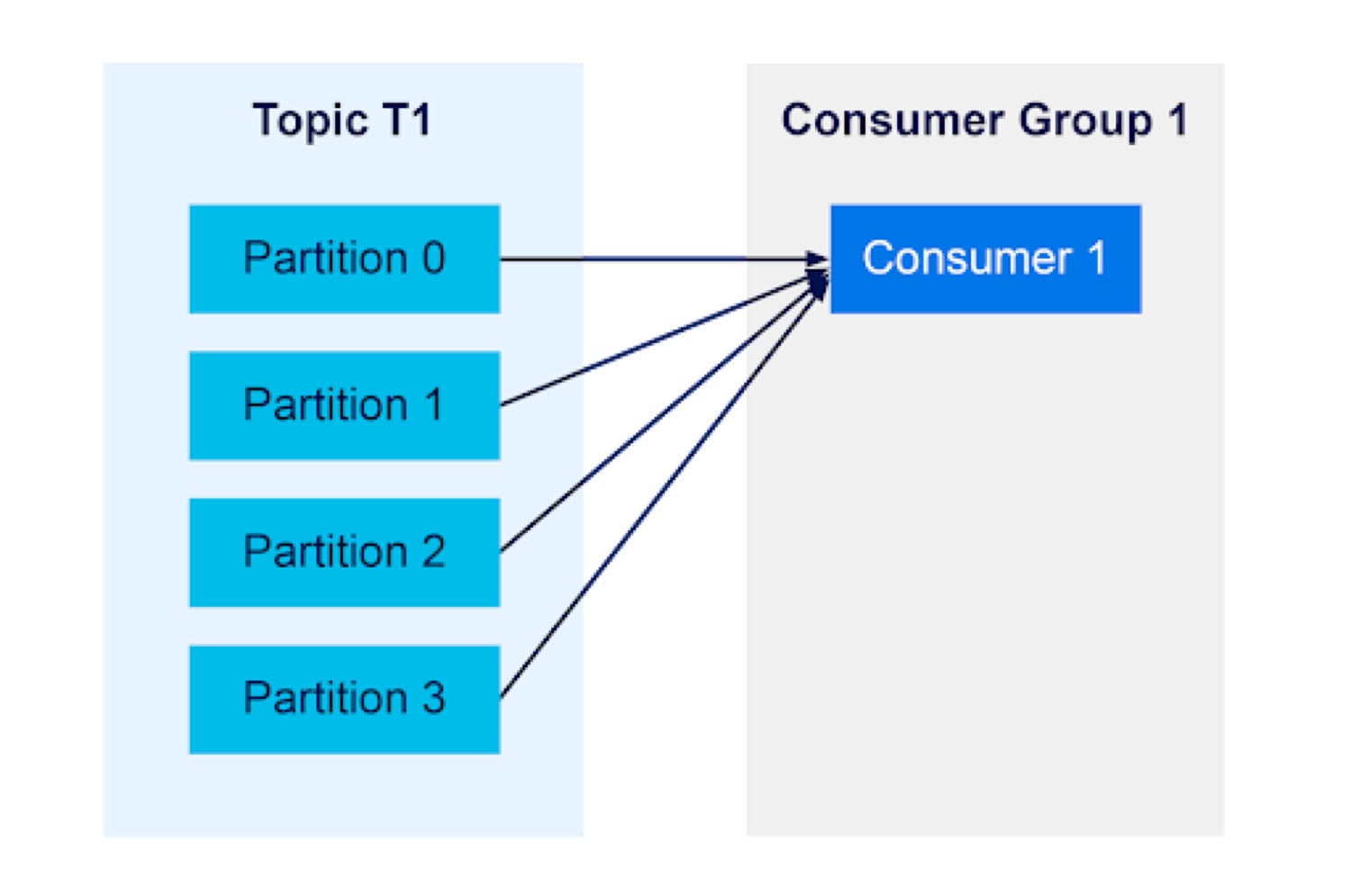 Instaclustr
InstaclustrA consumer group with two consumers will each receive messages from half of the topic partitions:
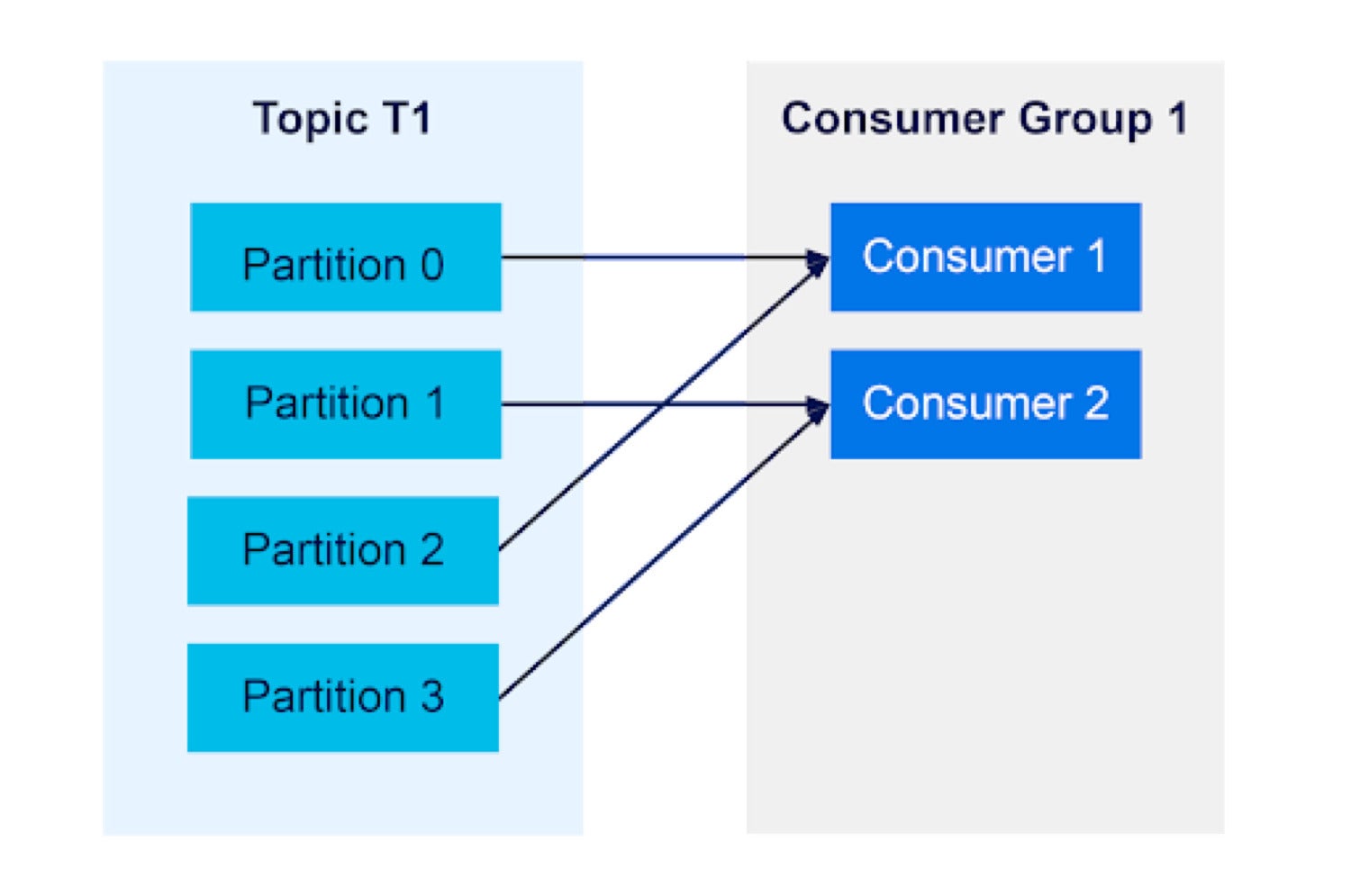 Instaclustr
InstaclustrConsumer groups will balance their consumers across partitions, up until the ratio is 1:1:
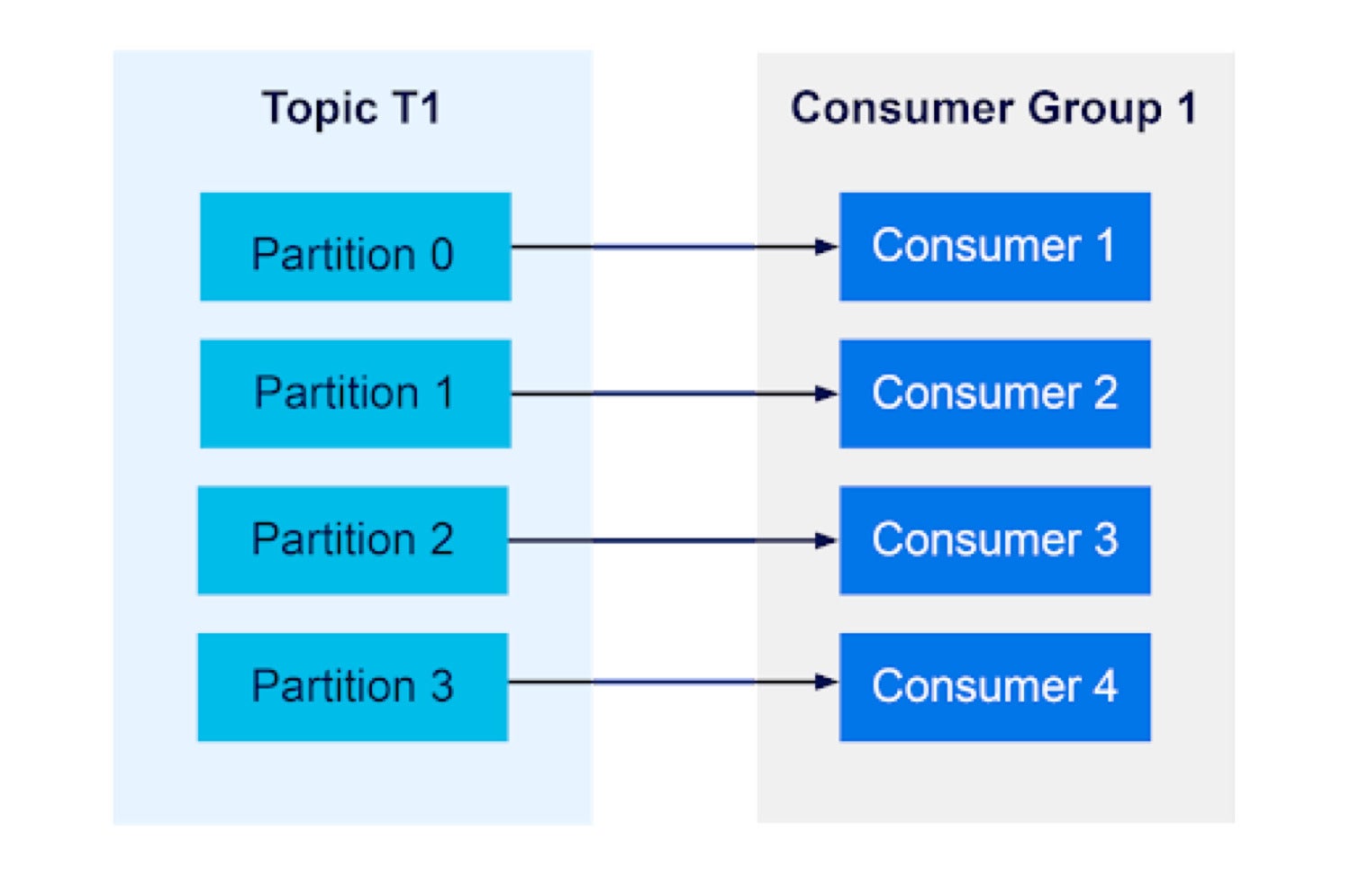 Instaclustr
InstaclustrHowever, if there are more consumers than partitions, any extra consumers will not receive messages:
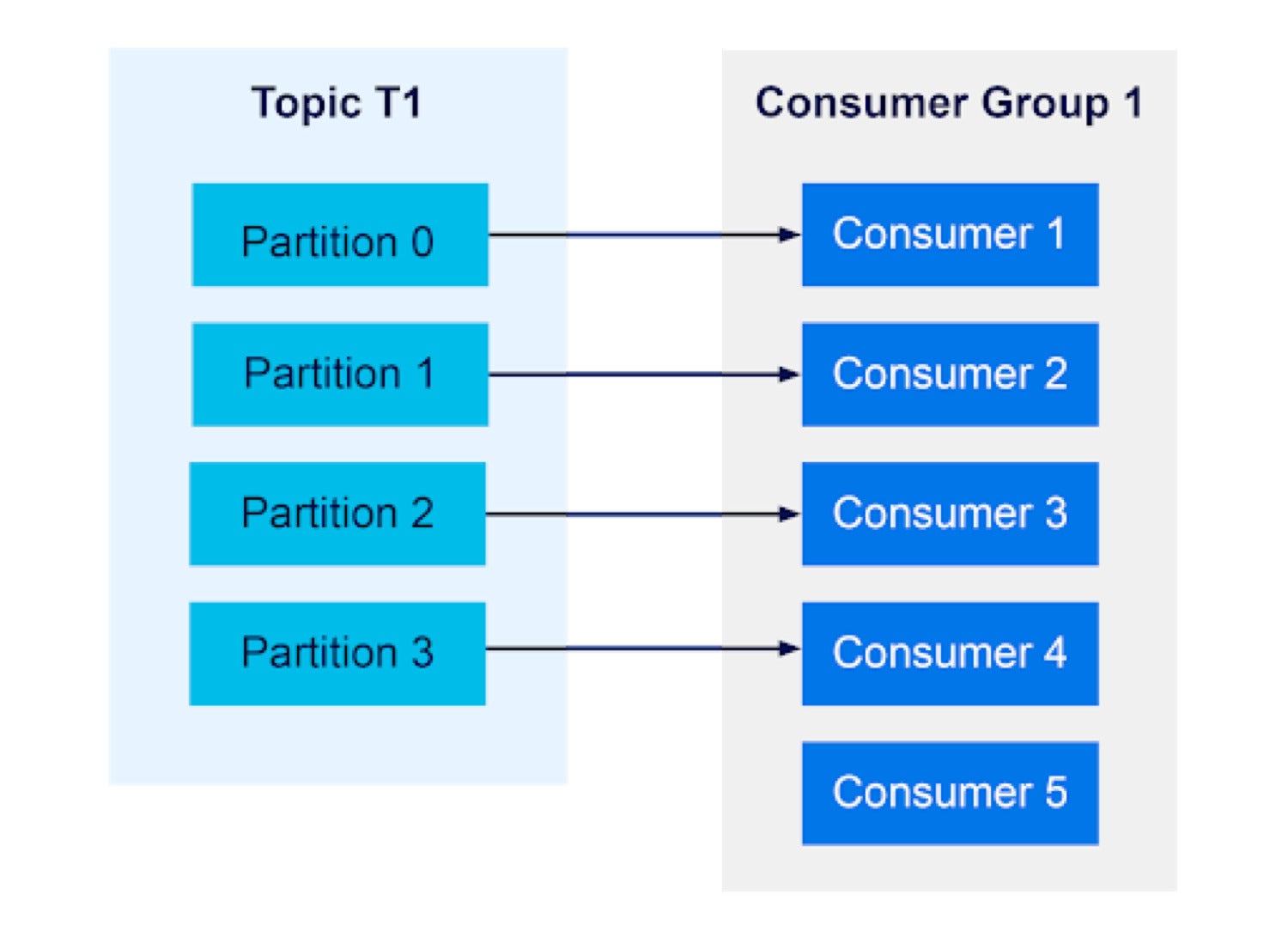 Instaclustr
InstaclustrIf multiple consumer groups read from the same topic, each consumer group will receive messages independently of the other. In the example below, each consumer group receives a full set of all messages available on the topic. Having an extra consumer sitting on standby can be useful in case one of your other consumers crashes; the standby can pick up the extra load without waiting for the crashed consumer to come back online.
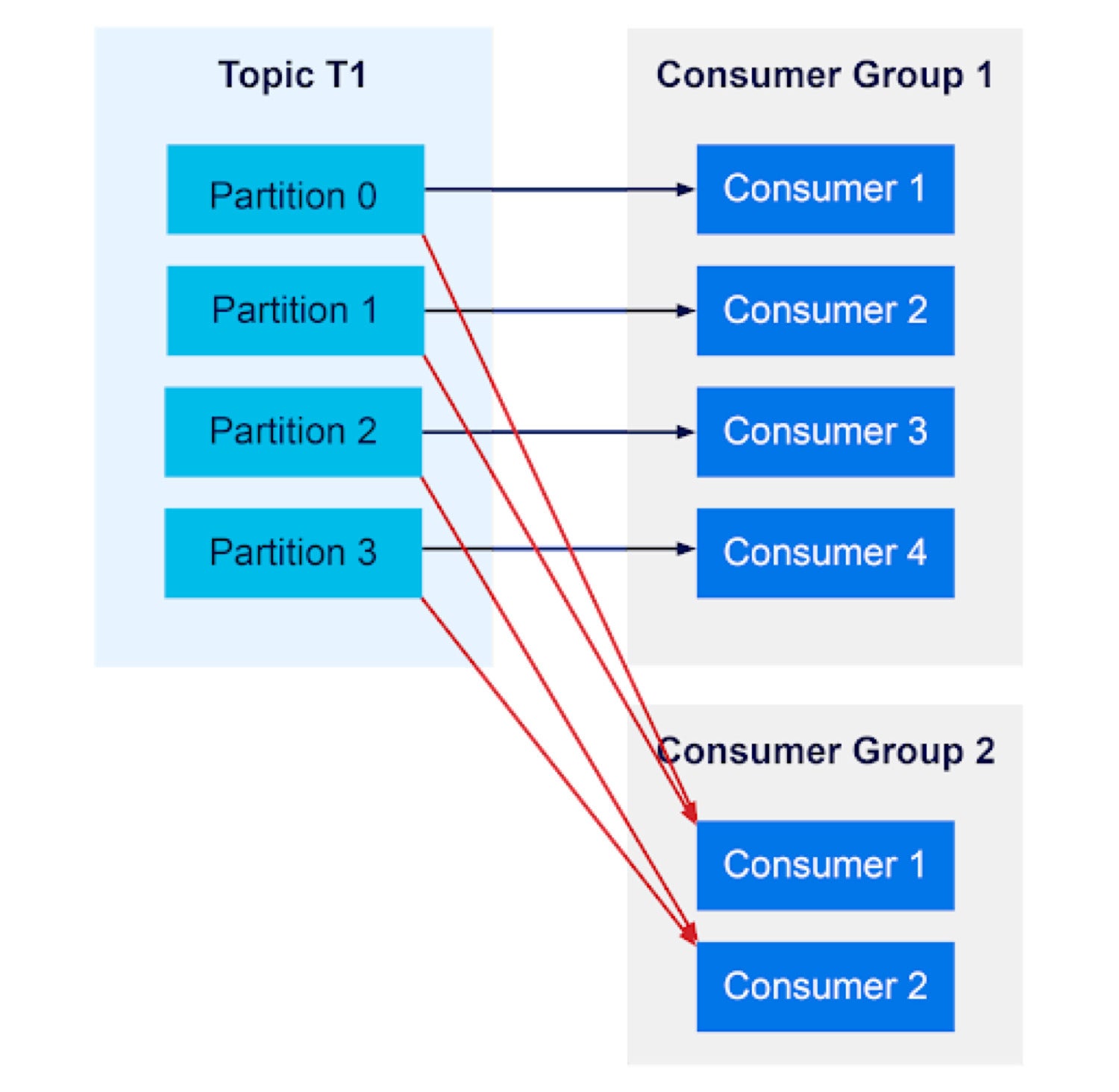 Instaclustr
InstaclustrConsumer group IDs, offsets, and commits
Consumer groups feature a unique group identifier, called a group ID. Consumers configured with different group IDs will belong to those different groups.
Rather than using an explicit method for keeping track of which consumer in a consumer group reads each message, a Kafka consumer keeps track of an offset: the position in the queue of each message it has read. There is an offset for every partition, in every topic, and for each consumer.
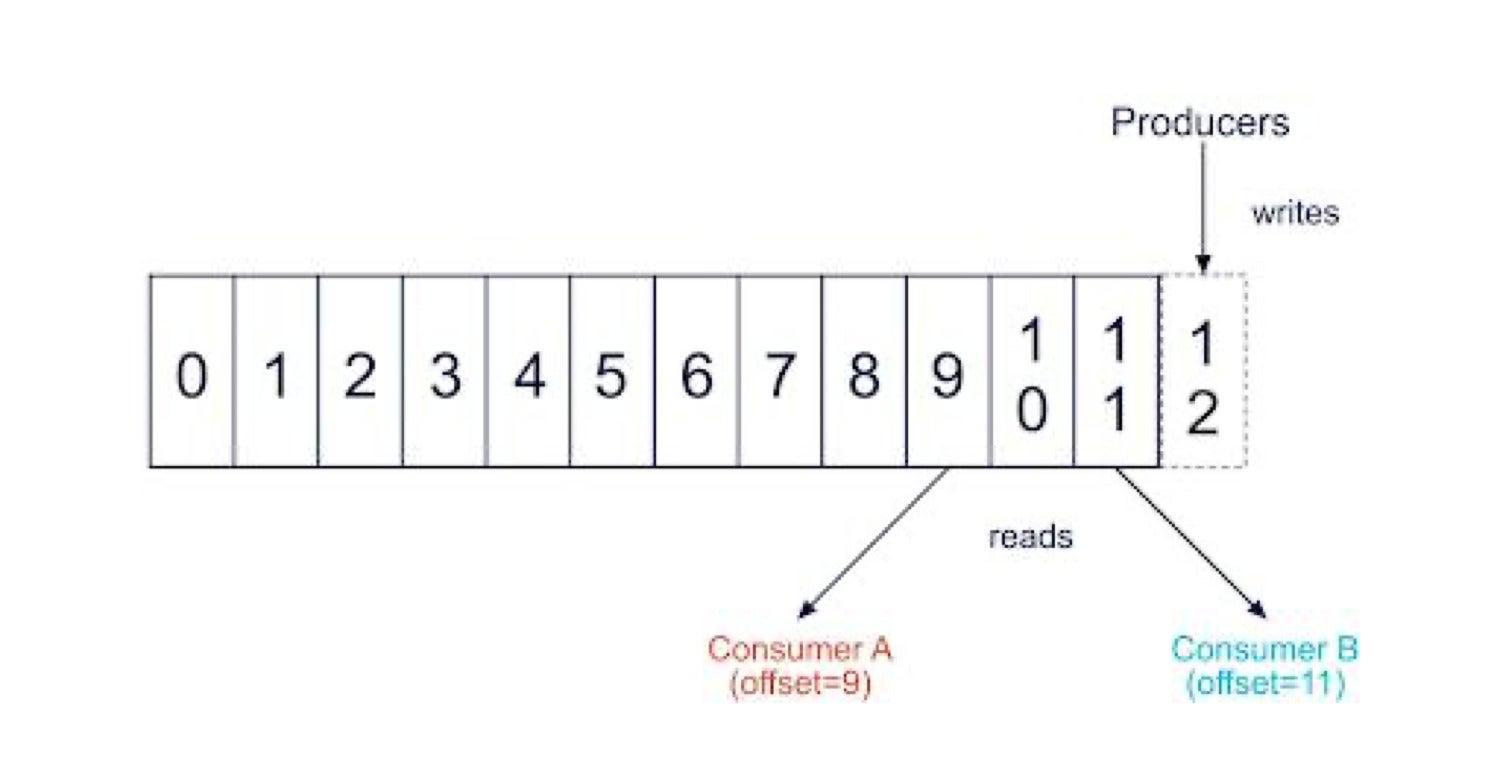 Instaclustr
InstaclustrUsers can choose to store those offsets themselves or let Kafka handle them. If you choose to let Kafka handle it the consumer will publish them to a special internal topic called __consumer_offsets.
Adding or removing a Kafka consumer from a consumer group
Within a Kafka consumer group, newly added consumers will check for the most recently committed offset and jump into the action—consuming messages formerly assigned to a different consumer. Similarly, if a consumer leaves the consumer group or crashes, a consumer that has remained in the group will pick up its slack and consume from the partitions formerly assigned to the absent consumer. Similar scenarios, such as a topic adding partitions, will result in consumers making similar adjustments to their assignments.
This rather helpful process is called rebalancing. It’s triggered when Kafka brokers are added or removed and also when consumers are added or removed. When availability and real-time message consumption are paramount, you may want to consider cooperative rebalancing, which has been available since Kafka 2.4.
How Kafka rebalances consumers
Consumers demonstrate their membership in a consumer group via a heartbeat mechanism. Consumers send heartbeats to a special Kafka topic, which is read by a Kafka broker acting as the group coordinator for that consumer group. When a set amount of time passes without the group coordinator seeing a consumer’s heartbeat, it declares the consumer dead and executes a rebalance.
Consumers must also poll the group coordinator within a configured amount of time, or be marked as dead even if they have a heartbeat. This can occur if an application’s processing loop is stuck, and can explain scenarios where a rebalance is triggered even when consumers are alive and well.
Between a consumer’s final heartbeat and its declaration of death, messages from the topic partition that the consumer was responsible for will stack up unread. A cleanly shut down consumer will tell the coordinator that it’s leaving and minimize this window of message availability risk; a consumer that has crashed will not.
The group coordinator assigns partitions to consumers
The first consumer that sends a JoinGroup request to a consumer group’s coordinator gets the role of group leader, with duties that include maintaining a list of all partition assignments and sending that list to the group coordinator. Subsequent consumers that join the consumer group receive a list of their assigned partitions from the group coordinator. Any rebalance will restart this process of assigning a group leader and partitions to consumers.
Kafka consumers pull… but functionally push when helpful
Kafka is pull-based, with consumers pulling data from a topic. Pulling allows consumers to consume messages at their own rates, without Kafka needing to govern data rates for each consumer, and enables more capable batch processing.
That said, the Kafka consumer API can let client applications operate under push mechanics, for example, receiving messages as soon as they’re ready, with no concern about overwhelming the client (although offset lag can be a concern).
Kafka concepts at a glance
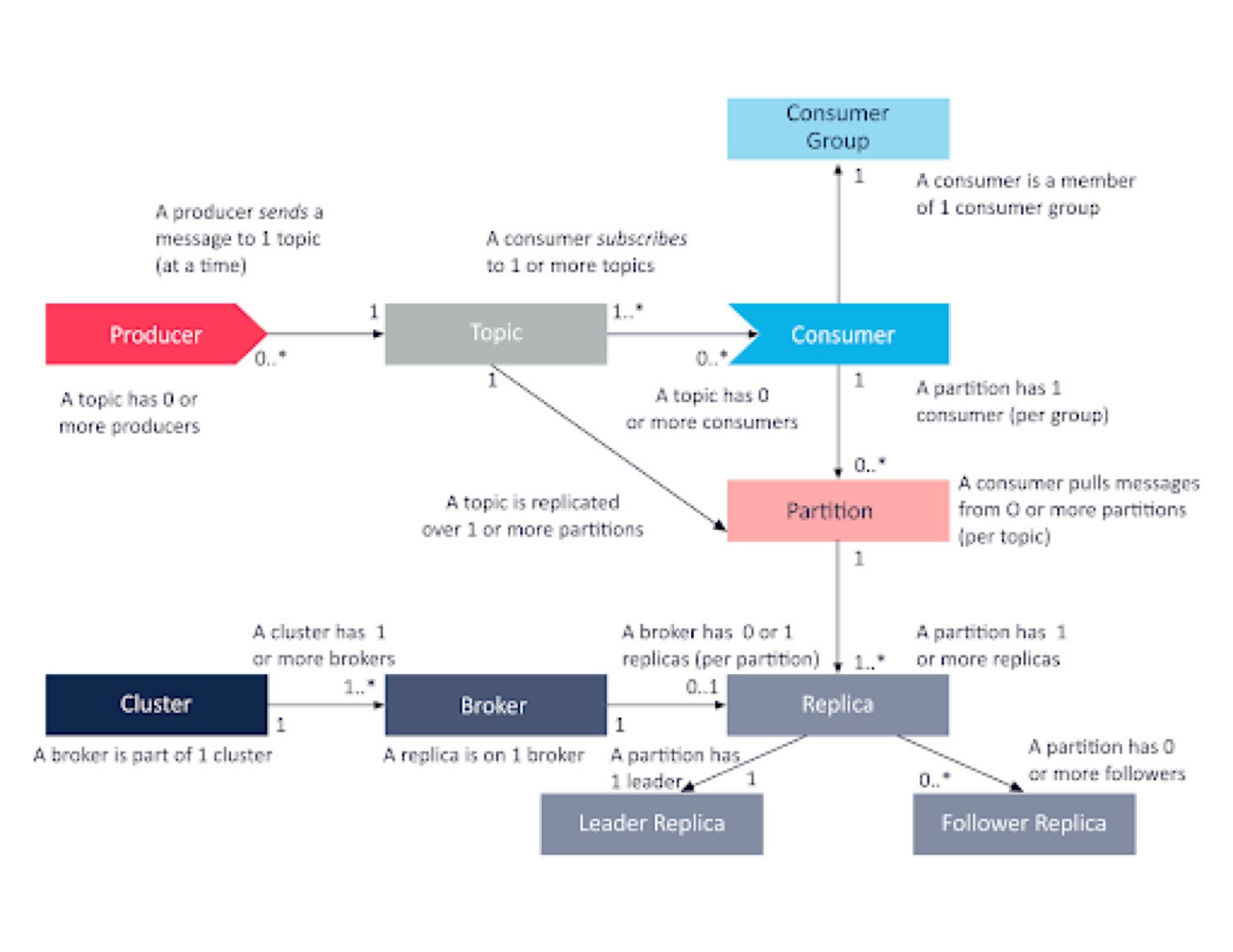 Instaclustr
InstaclustrThe above chart offers an easy-to-digest overview of Kafka consumers, consumer groups, and their place within the Kafka ecosystem. Understanding these initial concepts is the gateway to fully harnessing Kafka and implementing your enterprise’s own powerful real-time streaming applications and services.
Andrew Mills is an SSE at Instaclustr, part of Spot by NetApp, which provides a managed platform around open source data technologies. In 2016 Andrew began his data streaming journey, developing deep, specialized knowledge of Apache Kafka and the surrounding ecosystem. He has architected and implemented several big data pipelines with Kafka at the core.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.