

Bringing observability to the modern data stack
You can’t manage what you can’t measure. Just as software engineers need a comprehensive picture of the performance of applications and infrastructure, data engineers need a comprehensive picture of the performance of data systems. In other words, data engineers need data observability.
Data observability can help data engineers and their organizations ensure the reliability of their data pipelines, gain visibility into their data stacks (including infrastructure, applications, and users), and identify, investigate, prevent, and remediate data issues. Data observability can help solve all kinds of common enterprise data issues.
Data observability can help resolve data and analytics platform scaling, optimization, and performance issues, by identifying operational bottlenecks. Data observability can help avoid cost and resource overruns, by providing operational visibility, guardrails, and proactive alerts. And data observability can help prevent data quality and data outages, by monitoring data reliability across pipelines and frequent transformations.
Acceldata Data Observability Platform
Acceldata Data Observability Platform is an enterprise data observability platform for the modern data stack. It platform provides comprehensive visibility, giving data teams the real-time information they need to identify and prevent issues and make data stacks reliable.
Acceldata Data Observability Platform supports data sources such as Snowflake, Databricks, Hadoop, Amazon Athena, Amazon Redshift, Azure Data Lake, Google BigQuery, MySQL, and PostgreSQL. The Acceldata platform provides insights into:
- Compute – Optimize compute, capacity, resources, costs, and performance of your data infrastructure.
- Reliability – Improve data quality, reconciliation, and determine schema drift and data drift.
- Pipelines – Identify issues with transformation, events, applications, and deliver alerts and insights.
- Users – Real-time insights for data engineers, data scientists, data administrators, platform engineers, data officers, and platform leads.
The Acceldata Data Observability Platform is built as a collection of microservices that work together to manage various business outcomes. It gathers various metrics by reading and processing raw data as well as meta information from underlying data sources. It allows data engineers and data scientists to monitor compute performance and validate data quality policies defined within the system.
Acceldata’s data reliability monitoring platform allows you to set various types of policies to ensure that the data in your pipelines and databases meet the required quality levels and are reliable. Acceldata’s compute performance platform displays all of the computation costs incurred on customer infrastructure, and allows you to set budgets and configure alerts when expenditures reach the budget.
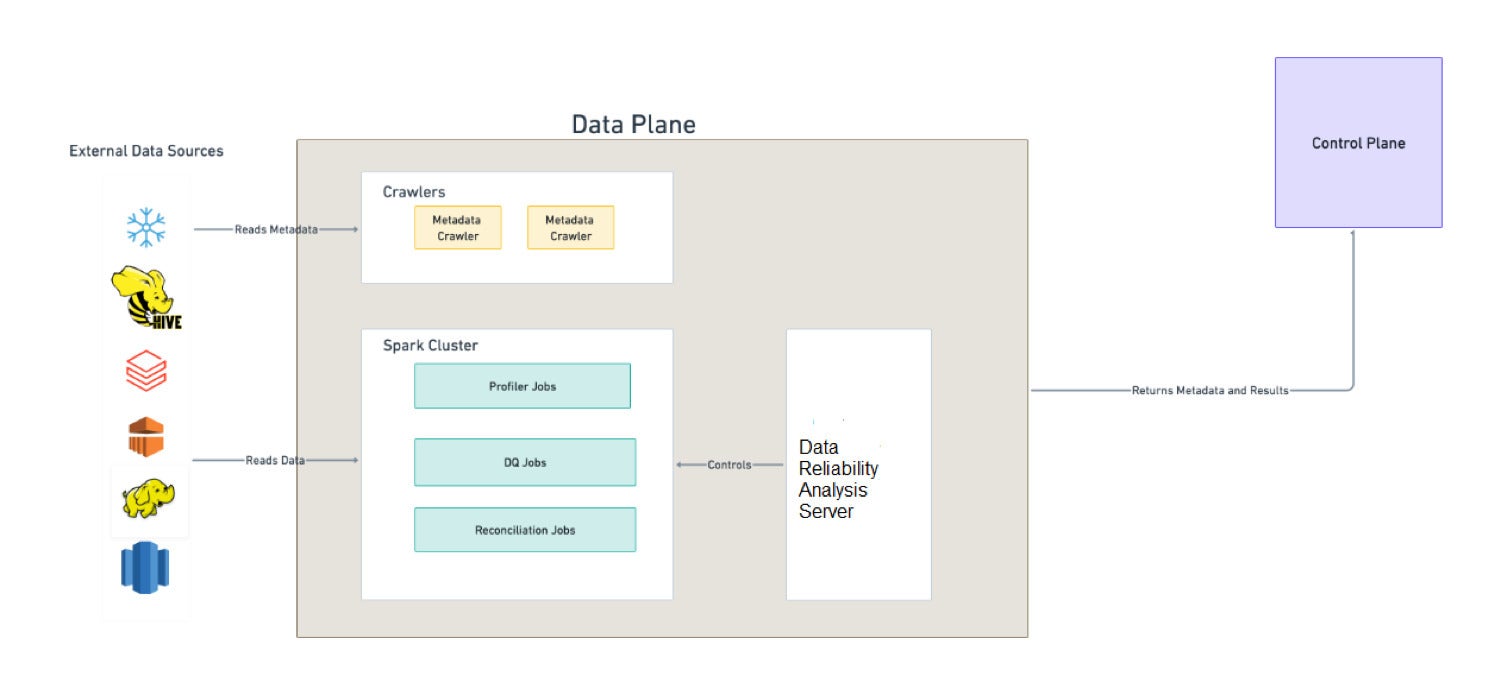
The Acceldata Data Observability Platform architecture is divided into a data plane and a control plane.
Data plane
The data plane of the Acceldata platform connects to the underlying databases or data sources. It never stores any data and returns metadata and results to the control plane, which receives and stores the results of the executions. The data analyzer, query analyzer, crawlers, and Spark infrastructure are a part of the data plane.
Data source integration comes with a microservice that crawls the metadata for the data source from their underlying meta store. Any profiling, policy execution, and sample data task is converted into a Spark job by the analyzer. The execution of jobs is managed by the Spark clusters.
 Acceldata
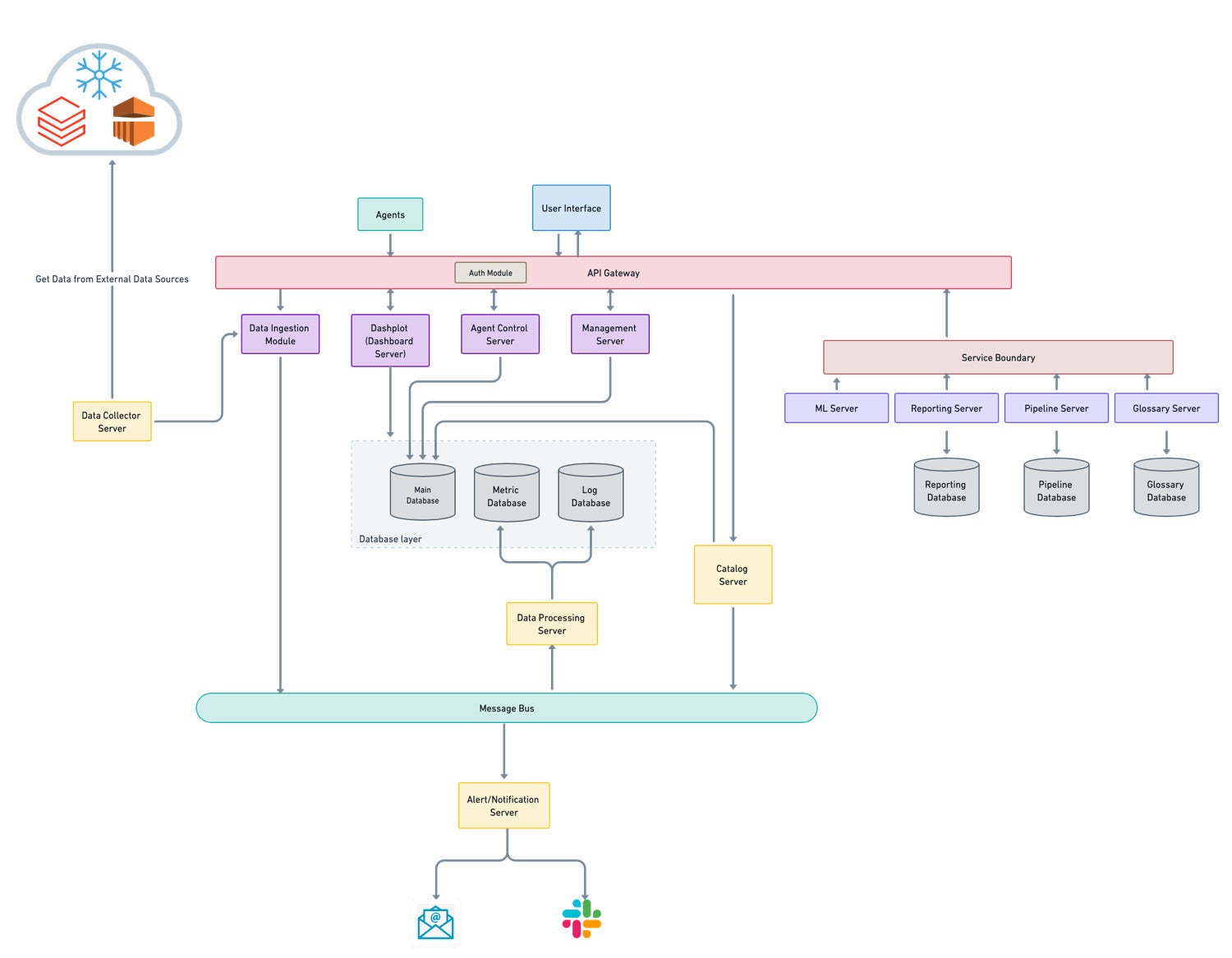
AcceldataControl plane
The control plane is the platform’s orchestrator, and is accessible via UI and API interfaces. The control plane stores all metadata, profiling data, job results, and other data in the database layer. It manages the data plane and, as needed, sends requests for job execution and other tasks.
The platform’s data computation monitoring section obtains the metadata from external sources via REST APIs, collects it on the data collector server, and then publishes it to the data ingestion module. The agents deployed near the data sources collect metrics regularly before publishing them to the data ingestion module.
The database layer, which includes databases like Postgres, Elasticsearch, and VictoriaMetrics, stores the data collected from the agents and data control server. The data processing server facilitates the correlation of data collected by the agents and the data collector service. The dashboard server, agent control server, and management server are the data computation monitoring infrastructure services.
When a major event (errors, warnings) occurs in the system or subsystems monitored by the platform, it is either displayed on the UI or notified to the user via notification channels such as Slack or email using the platform’s alert and notification server.
 Acceldata
AcceldataKey capabilities
Detect problems at the beginning of data pipelines to isolate them before they hit the warehouse and affect downstream analytics:
- Shift left to files and streams: Run reliability analysis in the “raw landing zone” and “enriched zone” before data hits the “consumption zone” to avoid wasting costly cloud credits and making bad decisions due to bad data.
- Data reliability powered by Spark: Fully inspect and identify issues at petabyte scale, with the power of open-source Apache Spark.
- Cross-data-source reconciliation: Run reliability checks that join disparate streams, databases, and files to ensure correctness in migrations and complex pipelines.
 Acceldata
AcceldataGet multi-layer operational insights to solve data problems quickly:
- Know why, not just when: Debug data delays at their root by correlating data and compute spikes.
- Discover the true cost of bad data: Pinpoint the money wasted computing on unreliable data.
- Optimize data pipelines: Whether drag-and-drop or code-based, single platform or polyglot, you can diagnose data pipeline failures in one place, at all layers of the stack.
 Acceldata
AcceldataMaintain a constant, comprehensive view of workloads and quickly identify and remediate issues through the operational control center:
- Built by data experts for data teams: Tailored alerts, audits, and reports for today’s leading cloud data platforms.
- Accurate spend intelligence: Predict costs and control usage to maximize ROI even as platforms and pricing evolve.
- Single pane of glass: Budget and monitor all of your cloud data platforms in one view.
 Acceldata
AcceldataComplete data coverage with flexible automation:
- Fully-automated reliability checks: Immediately know about missing, late, or erroneous data on thousands of tables. Add advanced data drift alerting with one click.
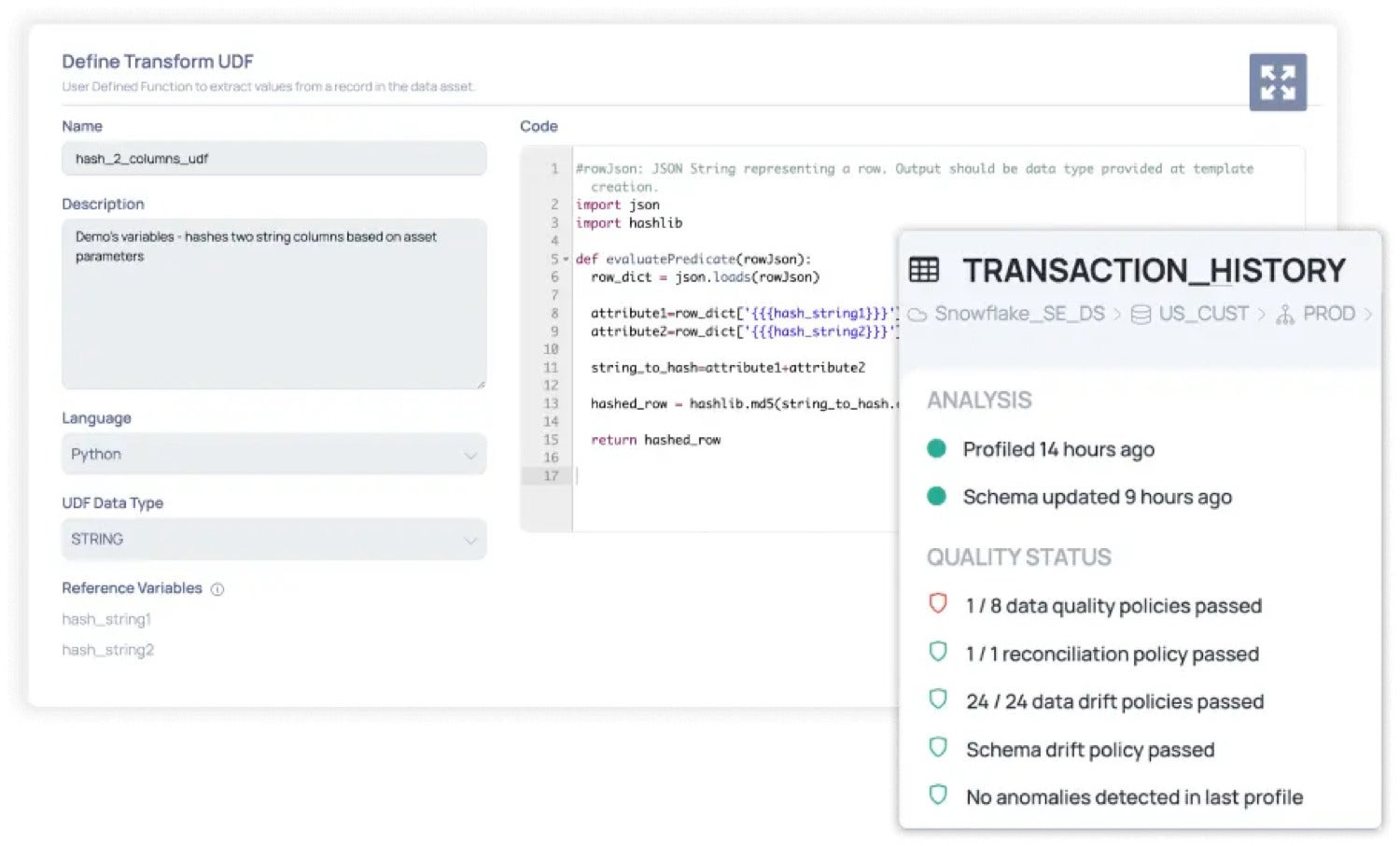
- Reusable SQL and user-defined functions (UDFs): Express domain centric reusable reliability checks in five programming languages. Apply segmentation to understand reliability across dimensions.
- Broad data source coverage: Apply enterprise data reliability standards across your company, from modern cloud data platforms to traditional databases to complex files.
 Acceldata
AcceldataAcceledata’s Data Observability Platform works across diverse technologies and environments and provides enterprise data observability for modern data stacks. For Snowflake and Databricks, Acceldata can help maximize return on investment by delivering insight into performance, data quality, cost, and much more. For more information visit www.acceldata.io.
Ashwin Rajeeva is co-founder and CTO at Acceldata.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.