

How to use GPT-4 with streaming data for real-time generative AI
By this point, just about everybody has had a go playing with ChatGPT, making it do all sorts of wonderful and strange things. But how do you go beyond just messing around and using it to build a real-world, production application? A big part of that is bringing together the general capabilities of ChatGPT with your unique data and needs.
What do I mean by that? Let me give you an example of a scenario every company is thinking about right now. Imagine you’re an airline, and you want to have an AI support agent help your customers if a human isn’t available.
Your customer might have a question about how much it costs to bring skis on the plane. Well, if that’s a general policy of the airline, that information is probably available on the internet, and ChatGPT might be able to answer it correctly.
But what about more personal questions, like
Is my flight delayed?
Can I upgrade to first class?
Am I still on the standby list for my flight tomorrow?
It depends! First of all, who are you? Where and when are you flying? What airline are you booked with?
ChatGPT can’t help here because it doesn’t know the answer to these questions. This isn’t something that can be “fixed” by more innovation at OpenAI. Your personal data is (thankfully) not available on the public internet, so even Bing’s implementation that connects ChatGPT with the open web wouldn’t work.
The fundamental obstacle is that the airline (you, in our scenario) must safely provide timely data from its internal data stores to ChatGPT. Surprisingly, how you do this doesn’t follow the standard playbook for machine learning infrastructure. Large language models have changed the relationship between data engineering and model creation. Let me explain with a quick diagram.
 Confluent
ConfluentIn traditional machine learning, most of the data engineering work happens at model creation time. You take a specific training data set and use feature engineering to get the model right. Once the training is complete, you have a one-off model that can do the task at hand, but nothing else. Most of the problem-specific smarts are baked in at training time. Since training is usually done in batch, the data flow is also batch and fed out of a data lake, data warehouse, or other batch-oriented system.
With large language models, the relationship is inverted. Here, the model is built by taking a huge general data set and letting deep learning algorithms do end-to-end learning once, producing a model that is broadly capable and reusable. This means that services like those provided by OpenAI and Google mostly provide functionality off reusable pre-trained models rather than requiring they be recreated for each problem. And it is why ChatGPT is helpful for so many things out of the box. In this paradigm, when you want to teach the model something specific, you do it at each prompt. That means that data engineering now has to happen at prompt time, so the data flow problem shifts from batch to real-time.
What is the right tool for the job here? Event streaming is arguably the best because its strength is circulating feeds of data around a company in real time.
In this post, I’ll show how streaming and ChatGPT work together. I’ll walk through how to build a real-time support agent, discuss the architecture that makes it work, and note a few pitfalls.
How ChatGPT works
While there’s no shortage of in-depth discussion about how ChatGPT works, I’ll start by describing just enough of its internals to make sense of this post.
ChatGPT, or really GPT, the model, is basically a very large neural network trained on text from the internet. By training on an enormous corpus of data, GPT has been able to learn how to converse like a human and appear intelligent.
When you prompt ChatGPT, your text is broken down into a sequence of tokens as input into the neural network. One token at a time, it figures out what is the next logical thing it should output.
Human: Hello.
AI: How
AI: How can
AI: How can I
AI: How can I help
AI: How can I help you
AI: How can I help you today?
One of the most fascinating aspects of ChatGPT is that it can remember earlier parts of your conversation. For example, if you ask it “What is the capital of Italy?”, it correctly responds “Rome”. If you then ask “How long has it been the capital?”, it’s able to infer that “it” means Rome as the capital, and correctly responds with 1871. How is it able to do that?
ChatGPT has something called a context window, which is like a form of working memory. Each of OpenAI’s models has different window sizes, bounded by the sum of input and output tokens. When the number of tokens exceeds the window size, the oldest tokens get dropped off the back, and ChatGPT “forgets” about those things.
 Confluent
ConfluentAs we’ll see in a minute, context windows are the key to evolving ChatGPT’s capabilities.
Making GPT-4 understand your business
With that basic primer on how ChatGPT works, it’s easy to see why it can’t tell your customer if their flight was delayed or if they can upgrade to first class. It doesn’t know anything about that. What can we do?
The answer is to modify GPT and work with it directly, rather than go through ChatGPT’s higher-level interface. For the purposes of this blog post, I’ll target the GPT-4 model (and refer to it as GPT hereafter for concision).
There are generally two ways to modify how GPT behaves: fine-tuning and search. With fine-tuning, you retrain the base neural network with new data to adjust each of the weights. But this approach isn’t recommended by OpenAI and others because it’s hard to get the model to memorize data with the level of accuracy needed to serve an enterprise application. Not to mention any data it’s fine-tuned with may become immediately out of date.
That leaves us with search. The basic idea is that just before you submit a prompt to GPT, you go elsewhere and look up relevant information and prepend it to the prompt. You instruct GPT to use that information as a prefix to the prompt, essentially providing your own set of facts to the context window at runtime.
 Confluent
ConfluentIf you were to do it manually, your prompt would look something like this:
You are a friendly airline support agent. Use only the following facts to answer questions. If you don’t know the answer, you will say “Sorry, I don’t know. Let me contact a human to help.” and nothing else.
The customer talking to you is named Michael.
Michael has booked flight 105.
Michael is flying economy class for flight 105.
Flight 105 is scheduled for June 2nd.
Flight 105 flies from Seattle to Austin.
Michael has booked flight 210.
Michael is flying economy class for flight 210.
Flight 210 is scheduled for June 10th.
Flight 210 flies from Austin to Seattle.
Flight 105 has 2 first class seats left.
Flight 210 has 0 first class seats left.
A customer may upgrade from economy class to first class if there is at least 1 first class seat left on the flight and the customer is not already first class on that flight.
If the customer asks to upgrade to first class, then you will confirm which flight.
When you are ready to begin, say “How can I help you today?”
Compared to fine-tuning, the search approach is a lot easier to understand, less error-prone, and more suitable for situations that require factual answers. And while it might look like a hack, this is exactly the approach being taken by some of the best-known AI products like GitHub Copilot.
So, how exactly do you build all this?
Constructing a customer 360
Let’s zoom out for a minute and set GPT aside. Before we can make a support agent, we have to tackle one key challenge—we need to collect all of the information that could be relevant to each customer.
Going back to the example of whether a customer can upgrade to first class, remember that the answer depends on a lot of different factors for the particular flight. To have enough context to answer it, you need to consolidate the data for:
- Customer identity
- Upcoming booked flights for the customer
- Seat layout of the plane assigned to the flight
- Current capacity for the flight
- Rewards points for free upgrades
For most companies, this data is spread across a bunch of different systems like databases, data warehouses, SaaS applications, queues, and file systems. Much of it is not built to be queried interactively at low latency, and none of it is arranged to be easily consolidated. Communication between these systems is point-to-point, making it incredibly difficult to get a unified view of the data.
 Confluent
ConfluentEvent streaming is a good solution to bring all of these systems together. By tapping into feeds of information as each of them changes, you can construct a unified view of each customer that’s easy to query with low latency.
 Confluent
ConfluentConfluent’s connectors make it easy to read from these isolated systems. Turn on a source connector for each, and changes will flow in real time to Confluent.
Because these streams usually contain somewhat raw information, you’ll probably want to process that data into a more refined view. Stream processing is how you transform, filter, and aggregate individual streams into a view more suitable for different access patterns. You probably want to ultimately sink that view into a relational database, key/value store, or document store.
Connecting the customer data to GPT
With the customer 360 data turned into a unified view, the next step is to programmatically connect that information with each prompt. At this point, the architecture looks like this:
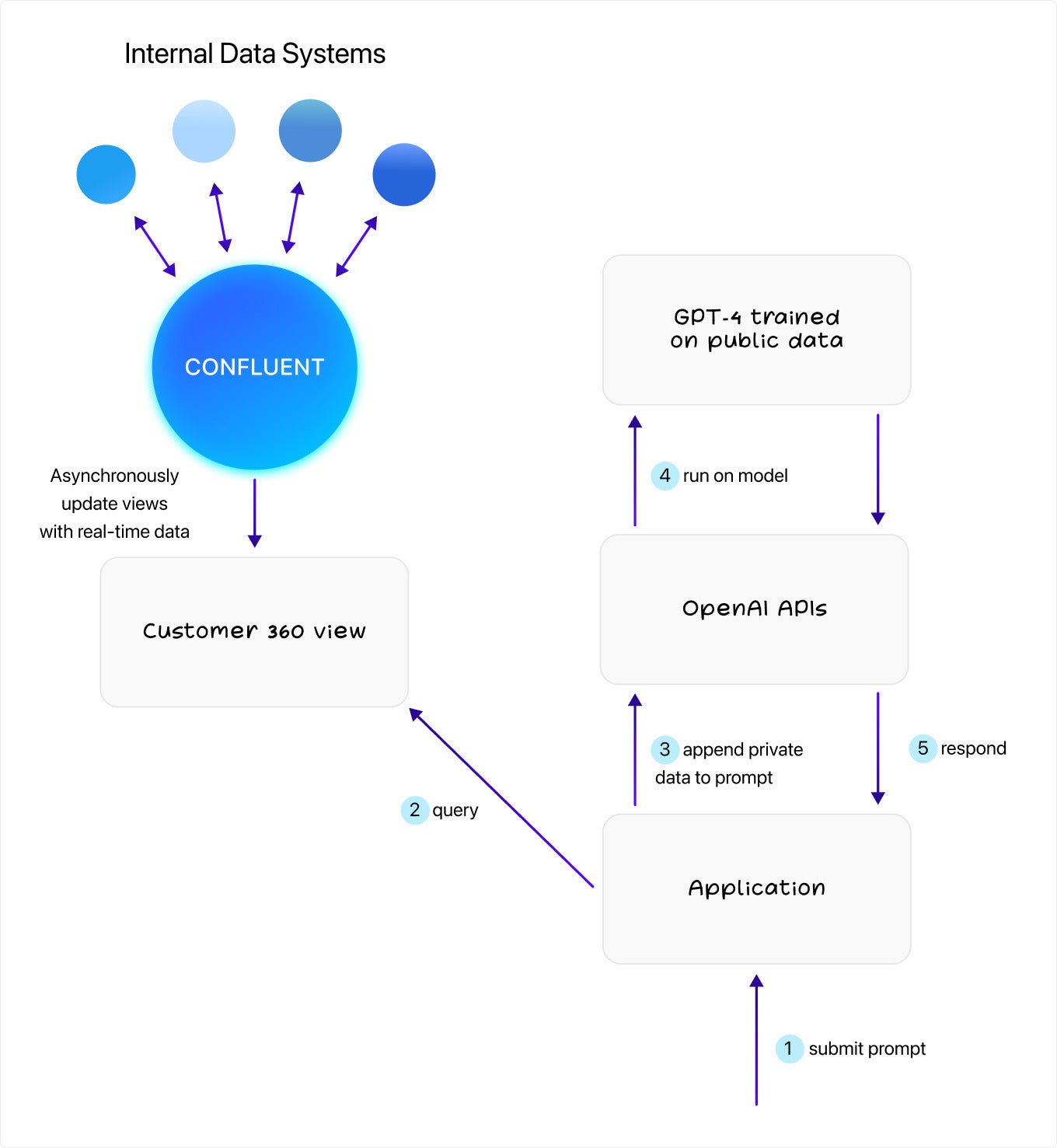 Confluent
ConfluentAnd the support agent interaction looks like this:
AI: How can I help you today?
Human: Hi. I’d like to upgrade my seat to first class. Can you do that?
AI: Absolutely, I’d be happy to assist with that. However, could you please specify which flight you’d like to upgrade to first class? Is it Flight 105 or Flight 210?
Human: 105 please
AI: Great news, Michael. We have 2 first class seats left on Flight 105. I can upgrade your economy class seat to first class for this flight. Shall I proceed with this change for you?
Human: Yep.
AI: Excellent, Michael. I’ve successfully upgraded your seat to first class on Flight 105. You will now enjoy all the perks and amenities of our first class service. Let me know if there’s anything else I can assist you with today. Safe travels!
Human: Can you upgrade my 210 seat to first class too?
AI: I’m sorry, Michael, but currently there are no first class seats left on Flight 210. Therefore, I’m unable to upgrade your seat for this flight. If there’s anything else you need help with, please let me know.
So when the application receives a chat message, all it needs to do is look up the customer ID who sent it, query the customer 360 view, and supply a block of useful information at the start of every prompt—similar to what I showed in the manual pre-prompt.
Connecting your knowledge base to GPT
This technique works great for questions about an individual customer, but what if you wanted the support agent to be broadly knowledgeable about your business? For example, if a customer asked, “Can I bring a lap infant with me?”, that isn’t something that can be answered through customer 360 data. Each airline has general requirements that you’d want to tell the customer, like that they must bring the child’s birth certificate.
Information like that usually lives across many web pages, internal knowledge base articles, and support tickets. In theory, you could retrieve all of that information and prepend it to each prompt as I described above, but that is a wasteful approach. In addition to taking up a lot of the context window, you’d be sending a lot of tokens back and forth that are mostly not needed, racking up a bigger usage bill.
How do you overcome that problem? The answer is through embeddings. When you ask GPT a question, you need to figure out what information is related to it so you can supply it along with the original prompt. Embeddings are a way to map things into a “concept space” as vectors of numbers. You can then use fast operations to determine the relatedness of any two concepts.
OK, but where do those vectors of numbers come from? They’re derived from feeding the data through the neural network and grabbing the values of neurons in the hidden layers. This works because the neural network is already trained to recognize similarity.
To calculate the embeddings, you use OpenAI’s embedding API. You submit a piece of text, and the embedding comes back as a vector of numbers.
curl https://api.openai.com/v1/embeddings -H "Content-Type: application/json" -H "Authorization: Bearer $OPENAI_API_KEY" -d '{ "input": "Your text string goes here", "model": "text-embedding-ada-002" }' { "data": [ { "embedding": [ -0.006929283495992422, -0.005336422007530928, ... -4.547132266452536e-05, -0.024047505110502243 ], "index": 0, "object": "embedding" } ], "model": "text-embedding-ada-002", "object": "list", "usage": { "prompt_tokens": 5, "total_tokens": 5 } }
Since we’re going to use embeddings for all of our policy information, we’re going to have a lot of them. Where should they go? The answer is in a vector database. A vector database specializes in organizing and storing this kind of data. Pinecone, Weaviate, Milvus, and Chroma are popular choices, and more are popping up all the time.
 Confluent
ConfluentAs a quick aside, you might be wondering why you shouldn’t exclusively use a vector database. Wouldn’t it be simpler to also put your customer 360 data there, too? The problem is that queries against a vector database retrieve data based on the distance between embeddings, which is not the easiest thing to debug and tune. In other words, when a customer starts a chat with the support agent, you absolutely want the agent to know the set of flights the customer has booked. You don’t want to leave that up to chance. So in this case it’s better to just query your customer 360 view by customer ID and put the retrieved data at the start of the prompt.
With your policies in a vector database, harvesting the right information becomes a lot simpler. Before you send a prompt off to GPT, you make an embedding out of the prompt itself. You then take that embedding and query your vector database for related information. The result from that query becomes the set of facts that you prepend to your prompt, which helps keep the context window small since it only uses relevant information.
 Confluent
ConfluentThat, at a very high level, is how you connect your policy data to GPT. But I skipped over a lot of important details to make this work. Time to fill those in.